Matryoshka Embeddings - Finding the sweet spot between Embedding size and retrieval quality for Qwen3 0.6b
2025-06-28
We all know about Matryoshka embeddings. If not, its basically the way an embeddings model is trained where we can truncate the embeddings to a given size and still have not so much of a quality drop. There are a lot of advantages of truncating the embeddings to a lower size. One of them being; its cheaper to store the vectors. This becomes important as we scale things up for search. When we have a model that gives out a vector of size 1024 and have to store millions of documents that cost of storing those can add up quite considerably. Especially when we have to store the vectors in memory for low latency. So Matryoshka Representation learning can help us bring down storage costs along with having a minimal quality drop.
But the question, how much smaller can we go? Obviously just like most things in life, there is a trade-off between quality and compute/storage. This blog is about answering that.
Choosing a model (that provides a outputs size of 1024 for example); how small can I slice to optimize trade-off?
Heavily inspired from the Hybrid Search post from the vespa team. I thought, lets take a small dataset, brute force the evaluation with different embeddings size and find out.
So I did exactly that in this notebook. And I wanted to test out the most recent new Qwen3 Embeddings 0.6B model.
The testing set I used was the BEIR slice of nfcorpus. I calculated the embeddings at full capacity of 1024. And tested right from 1 to 1024 embeddings size on the test set; with my evaluation method to be nDCG@10. While I do realize the model isn’t designed to go smaller than 32; I was curious on the performance in smaller sizes.
The results were quite surprising.
Some things to keep in mind before getting to the results:
- The test set is pretty small but a well respected benchmark.
- nDCG@10 may change with different HSNW configurations. I used chromaDB for the graph
- Source code present in the github repo.
- Ranking is a very data specific task. Similar results might not be reproducible with a different dataset.
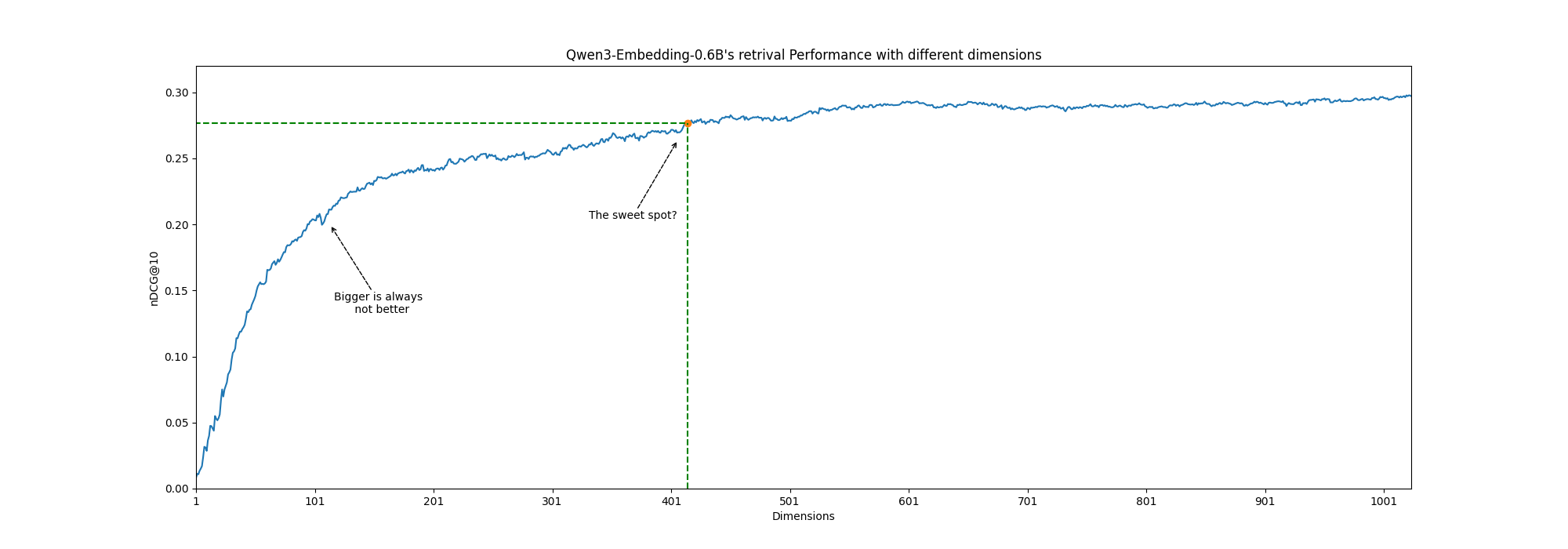
Results:
 Please open image in new tab for better view
Please open image in new tab for better view
Bigger is not always better:
Obviously, if we dont slice the embeddings at all; we see the higest score. But around the 100-120 range the performance actually goes down. So if someone was considering a 120 size embeddings, it would be better to go lower to 100 than 120.
Similarly the quality doesnt always increase with dimensions. 762-766 provides better retrieval than 768-774. The increase is always not linear. Or maybe I am being a bit too picky?
The sweet spot
Now, it depends on the retrieval use case but for me, its seems like is around the early 400 range is a good trade off. I say this because the incremental gain above 450 might be too costly in a resource constrained environment.
Also above the 650 the gain becomes very small. Almost next to nothing.
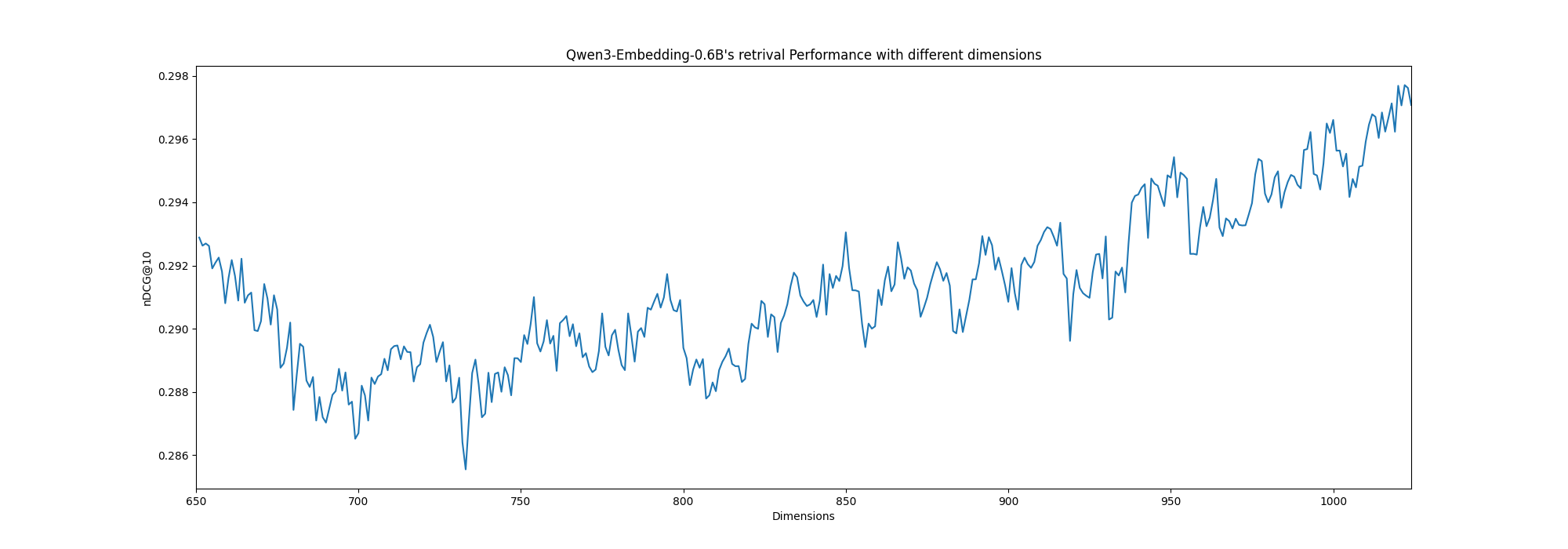
Drilling Down
If we wanted to go crazy and also check how its behaving above 650 in a more granular way:
 Please open image in new tab for better view
Please open image in new tab for better view
Again, we are looking into numbers that are very close to each other.
Finally
The goal here was not to find the perfect embedding size; but to understand if the quality reduction was considerable on size reduction. We can almost half the embedding size and not make the retrieval quality really bad. Which is huge because cutting memory into half is worth exploring. We need a lot more scrutiny here (larger datasets, multiple ranking metrics etc). But I will be using a 512 (for some reason I like this number) on my retrieval tasks.
If given the choice of either use a single 1024 model or 2 models trained differently but support MLR; I will always pick the latter.
Let me know if I missed/got something wrong here.